What is a Robots.txt file, and what is it used for?
A Robots.txt file tells search engine spiders or crawlers not to crawl or crawl certain pages or sections of a website. Most major search engines (including Google, Bing, and Yahoo) recognize and obey Robots.txt requests.
Why is a Robots.txt file important?
Most websites don’t need a robots.txt file. This is because Google can find and index all the important pages on a site.
Search engines don’t automatically index unimportant pages or duplicates of other pages.

What is CPC?
However, there are three main reasons to use a robots.txt file:
Blocking non-public pages
Sometimes, you have pages on your site that you don’t want to be indexed. For example, you might have a shopping cart page for an online store or a login page for site administrators. These pages are required to exist, but you don’t want people to access them directly through search engines. In these cases, use a robots.txt file to hide these pages from crawlers and search engine bots.
Maximize Crawl Budget
If you’re having trouble getting all your pages indexed, you might be facing a crawl budget issue. By blocking unimportant pages with a robots.txt file, you’re allowing Googlebot to spend more of your site’s crawl budget on essential pages.
Preventing Resources from Being Indexed
Meta directives prevent pages from being indexed, just like robots.txt. However, these meta-robots don’t work very well with multimedia resources, such as PDFs and images. This is where robots.txt comes in.
In short, a Robots.txt file tells search engine spiders not to crawl certain pages on your website.
You can check the number of indexed pages in Google Search Console.
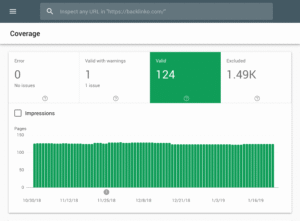
If the number matches the number of pages you want indexed, then you don’t need a Robots.txt file.
But if the number is higher than you expected (and you notice URLs indexed that shouldn’t be indexed), it’s time to create a robots.txt file for your website.
Best practices for creating a Robots.txt file
Create a Robots.txt file.
The first step is to create a Robots.txt file.
This text file can also be created using Windows Notepad. No matter how you end up making your robots.txt file, the format is the same:
User-agent: X
Disallow: Y
The user agent is the specific bot you’re talking to.
And anything after “Disallow” is the page or section you want to block from being indexed.
What is Anchor Text? Its Importance in SEO
Here’s an example:
User-agent: googlebot
Disallow images/
This rule tells Googlebot not to index the images folder on your website.
You can also use an asterisk (*) to tell all bots that visit your website.
Here’s an example:
User-agent: *
Disallow: /images
The “*” tells all spiders not to crawl your images folder.
This is just one way to use a robots.txt file. For more information on blocking specific pages on your site from being crawled by robots, see Google’s help table.

Make it easy to find your Robots.txt file.
Once you’ve created your robots.txt file, give it a try. Technically, you can put it in any of your site’s leading directories.
But to increase your chances of finding it, we recommend placing it at this address:
https://example.com/robots.txt
Note that robots.txt is case-sensitive. So, make sure to use a lowercase “r” in the file name.
Check for errors
Your robots.txt file needs to be set up correctly. One mistake can prevent your entire site from being indexed.
Fortunately, you don’t have to worry about setting up the code correctly. Google has a tool called the Robots Testing Tool that you can use:
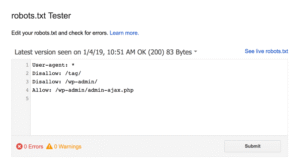
This tool will display the robots.txt file and any errors or warnings as follows:

As you can see in the example above, we have prevented spiders from crawling the WP admin page.
We also used the robots.txt file to prevent WordPress auto-generated tags from crawling pages to avoid duplicate content.
Robots.txt vs. Meta Directives
Why use a robots.txt file when you can block pages at the page level with the “noindex” meta tag?
As we mentioned earlier, the noindex tag is not effective for multimedia resources, such as videos and PDF files.
Additionally, if you want to block thousands of pages on your site, it’s easier to block the entire site with robots.txt instead of manually adding a noindex tag to each page.
You should also avoid wasting the crawl budget by having Google crawl pages with ‘noindex’ tags.
Outside of the above three cases, we recommend using meta directives instead of robots.txt because they are easier to implement and less likely to cause a disaster (like blocking the entire site).